
当迪米特里斯·帕帕伊利奥波洛斯第一次要求 ChatGPT 解释图像中的颜色时,他想到的是“那条裙子”——2015 年在互联网上引起轰动的臭名昭著的迷惑性光学错觉照片。帕帕伊利奥波洛斯是威斯康星大学麦迪逊分校计算机工程系的副教授,他研究的是支撑 聊天机器人(如 OpenAI 的 ChatGPT 和谷歌的 Gemini)的人工智能类型。他很好奇这些 AI 模型会对欺骗人脑的错觉做出何种反应。
人类视觉系统已经适应将物体感知为具有一致的颜色,以便我们仍然可以在不同的光照条件下识别物品。在我们的眼中,叶子在明媚的中午和橙色的日落中看起来都是绿色的——即使叶子随着时间的推移反射不同的光波长。这种适应性使我们的大脑拥有了各种巧妙的方式来看见错误的颜色,其中许多导致了熟悉的光学错觉,例如,当被圆柱体阴影遮蔽时,看起来图案始终如一的棋盘(但并非如此)——或者物体,例如当分层扭曲条纹时,可口可乐罐会错误地以其熟悉的颜色出现。
在一系列测试中,帕帕伊利奥波洛斯观察到 GPT-4V(ChatGPT 的最新版本)似乎会像人一样被许多相同的视觉欺骗所愚弄。聊天机器人的答案通常与人类的感知相符——不是识别图像中像素的实际颜色,而是描述一个人可能看到的相同颜色。即使是帕帕伊利奥波洛斯创建的照片也是如此,例如一张蓝色滤镜下的生鱼片,仍然看起来是粉红色的。这张特殊的图像是颜色恒常性错觉的一个例子,以前从未在网上发布过,因此不可能包含在任何 AI 聊天机器人的训练数据中。
支持科学新闻
如果您喜欢这篇文章,请考虑通过以下方式支持我们屡获殊荣的新闻报道 订阅。通过购买订阅,您正在帮助确保有关当今塑造我们世界的发现和想法的具有影响力的故事的未来。

目标物的图片(左)和显示颜色恒常性错觉的蓝色滤镜图像(右)。尽管经过处理的版本中的靶心看起来是红色的,但实际上,它的像素具有更大的蓝色和绿色值。(蓝色滤镜是使用 Akiyoshi Kitaoka 创建的工具应用的。)
krisanapong detraphiphat/Getty Images(照片);Akiyoshi Kitaoka 的直方图压缩(蓝色滤镜)
帕帕伊利奥波洛斯指出,“这不是一项科学研究”,只是一些随意的实验。但他说,聊天机器人令人惊讶的类人反应没有明确的解释。起初,他想知道 ChatGPT 是否会清理原始图像,以使其处理的数据更加统一。然而,OpenAI 在一封电子邮件中告诉大众科学,ChatGPT 在 GPT-4V 解释输入图像之前,不会微调输入图像的色温或其他特征。在没有这种直接解释的情况下,帕帕伊利奥波洛斯说,视觉语言 Transformer 模型有可能已经学会了在上下文中解释颜色,评估图像中的物体相对于彼此,并相应地评估像素,这与人脑所做的事情类似。
布莱克·理查兹是麦吉尔大学计算机科学和神经科学副教授,他同意该模型可能像人类一样在上下文中学习颜色,识别物体并响应该类型物品通常出现的方式。例如,在“那条裙子”的案例中,科学家认为,不同的人根据他们对照亮织物的光源的假设,以两种不同的方式(金色和白色或蓝色和黑色)解释了颜色。
理查兹说,AI 模型能够以类似细致的方式解释图像,这一事实有助于我们理解人们可能如何发展相同的技能。“它告诉我们,我们自己这样做的倾向几乎肯定是简单接触数据的结果,”他解释道。如果一个算法被输入大量的训练数据,开始主观地解释颜色,这意味着人类和机器的感知可能是非常一致的——至少在这一个方面是这样。
然而,正如最近的研究表明,在其他情况下,这些模型的行为完全不像我们——这一事实揭示了人和机器“看”世界方式之间的关键差异。一些研究人员发现,新开发的视觉语言 Transformer 模型对错觉的反应不一致。有时它们的反应与人类相同;在其他情况下,它们提供纯粹逻辑和客观准确的反应。有时它们会用完全胡说八道来回答,这可能是幻觉的结果。
这些研究背后的动机不是为了证明人类和 AI 是相似的。一个根本的区别是,我们的大脑充满了非线性连接和反馈回路,这些回路来回传递信号。正如我们的眼睛和其他感觉系统从外部世界收集信息一样,这些迭代网络“帮助我们的大脑填补任何空白”,安大略省约克大学的计算神经科学家 乔尔·齐尔伯伯格说道,他没有参与光学错觉研究。尽管已经开发了一些循环神经网络来模仿人脑的这一方面,但许多机器学习模型并非旨在具有重复的、双向的连接。最流行的生成式 Transformer AI 模型依赖于“前馈”的数学函数。这意味着信息仅在一个方向上通过它们移动:从输入到输出。
研究这种 AI 系统对光学错觉的反应,可以帮助计算机科学家更好地理解这些单向机器学习模型的能力和偏见。它可以帮助 AI 研究人员专注于复发之外的哪些因素与模仿人类反应有关。
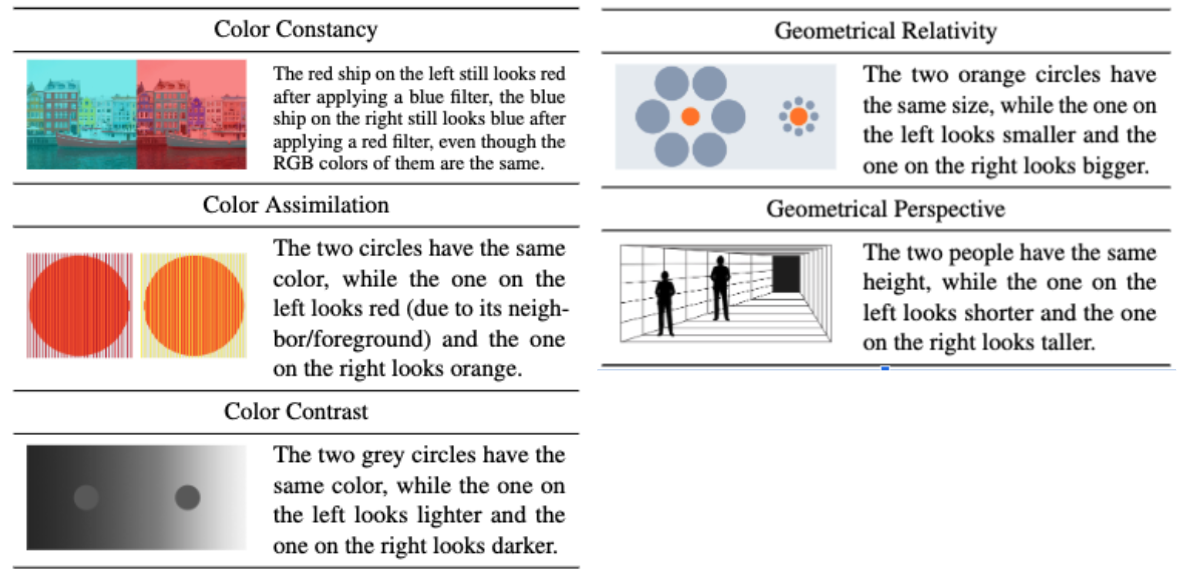
一个潜在的因素是模型的大小,根据一个计算机科学家团队的说法,该团队评估了四个开源视觉语言模型,并在 2023 年 12 月的会议上展示了其发现。研究人员发现,较大的模型,即那些使用更多权重和变量(决定响应)开发的模型,比小型模型更接近人类对光学错觉的反应。总体而言,科学家测试的 AI 模型在专注于图像中的错觉元素方面表现不佳(平均准确率低于 36%),并且平均只有约 16% 的情况下与人类反应一致。然而,该研究还发现,模型在响应某些类型的错觉时比其他类型的错觉更接近人类。
例如,要求这些模型评估透视错觉,产生了最像人类的输出。在透视错觉中,图像中大小相等的物体在背景暗示三维深度时,看起来具有不同的大小。模型被要求判断图像中物体轮廓的相对大小——研究人员还重复了成对和翻转图像的测试,以检测模型响应中任何潜在的右侧或左侧偏差。如果机器人对所有问题的回答都与标准的人类感知相符,研究作者将其视为“类人”。对于一种提示类型,即衡量模型在图像中定位物体的能力,在响应透视错觉方面,测试的两个模型高达 75% 具有类人水平。在其他测试和其他模型中,类人反应的比率要低得多。
{kind=link}
在 3 月份发布的一项单独的预印本研究中,研究人员测试了 GPT-4V 和谷歌的 Gemini-Pro 评估 12 种不同类别的光学错觉的能力。这些类别包括不可能物体错觉,它是三维空间中不存在的物体的二维图形,以及隐藏图像错觉,其中物体的轮廓包含在图像中,但并不立即明显。在 12 个类别中的 9 个类别中,与人相比,这些模型在查明错觉中发生的事情方面表现更差,平均准确率为 59%,而人类受访者的准确率为 94%。但在三个类别——颜色、角度和大小错觉——GPT-4V 的表现与人类审阅者相当,甚至略好于人类审阅者。
该研究的作者之一、亚马逊网络服务公司 AI 实验室的应用科学家瓦西·艾哈迈德认为,差异在于分析错觉是否需要定量或定性推理。人类擅长两者。另一方面,机器学习模型可能不太擅长根据无法轻易衡量的东西做出判断,艾哈迈德说。AI 系统最擅长解释的所有三个错觉类别都涉及可量化的属性,而不仅仅是主观感知。
密歇根大学计算机科学教授兼 AI 研究员、2023 年 12 月会议上提出的预印本的高级作者乔伊斯·柴说,为了负责任地部署 AI 系统,我们需要了解它们的漏洞和盲点,以及人类倾向将在何处以及何处不会被复制。“模型与人类保持一致可能是好事也可能是坏事,”她说。在某些情况下,模型减轻人类偏见是可取的。例如,分析放射影像的 AI 医疗诊断工具最好不要容易受到视觉错误的影响。
然而,在其他应用中,AI 模仿某些人类偏见可能是有益的。理查兹指出,我们可能希望自动驾驶汽车中使用的 AI 视觉系统与人类错误相匹配,以便车辆错误更容易预测和理解。“自动驾驶汽车的最大危险之一不是它们会犯错误。人类一直在犯驾驶错误,”他说。但他担心自动驾驶汽车的是它们的“奇怪错误”,道路上已建立的安全系统尚未准备好处理这些错误。
OpenAI 的 GPT-4V 和其他大型机器学习模型通常被描述为黑匣子——提供输出但没有解释的不透明系统——但光学错觉这种非常人性化的现象可能会让我们一窥其内部。