
今天,世界上几乎一半的人口说印欧语,这种语言的起源可以追溯到数千年前的单一原始语言。英语、俄语、印度斯坦语、拉丁语和梵语等截然不同的语言都可以追溯到这种祖先语言。
在过去的几百年里,语言学家已经弄清楚了很多关于第一种印欧语的知识,包括它使用的许多词汇和一些支配它的语法规则。在此过程中,他们提出了关于最初的 speakers 是谁,他们住在哪里和如何生活,以及他们的语言如何如此广泛传播的理论。
大多数语言学家认为,这些 speakers 是游牧的牧民,他们大约在 6000 年前居住在乌克兰和俄罗斯西部的草原上。然而,少数人将起源地放在更早的 2000 到 3000 年前,在安纳托利亚(现代土耳其地区)的农民社群中。现在,一项新的分析,使用了从进化生物学中借鉴的技术,已经倾向于后者,尽管草原在后期发挥了重要的作用。
支持科学新闻报道
如果您喜欢这篇文章,请考虑通过以下方式支持我们屡获殊荣的新闻报道 订阅。通过购买订阅,您正在帮助确保有关塑造我们当今世界的发现和思想的具有影响力的故事的未来。
新分析中使用的计算技术在语言学家中备受争议。但其支持者表示,它有望为该领域带来更严格的定量方法,并可能将关键日期推向更远的过去,就像放射性碳定年在考古领域所做的那样。
秘鲁天主教大学(位于利马)的历史语言学家保罗·赫加蒂说:“我认为语言学可能会迎来一场类似于放射性碳革命的变革。”他是新研究的合著者;他在 2021 年的《语言学年度评论》中描述了这种计算方法。
揭示死语言
为了理解正在发生的事情,了解印欧语研究的发展历程会有所帮助。
在 16 世纪,随着旅行和贸易使欧洲人接触到更多的外语,学者们对语言之间的关系以及它们的起源越来越感兴趣。
18 世纪后期,在印度的英国法官威廉·琼斯爵士注意到梵语、拉丁语和希腊语在词汇和语法上的相似之处,这不可能是巧合。
例如,英语单词“father”在梵语中是“pitar”,在拉丁语和希腊语中是“pater”。“Brother”在梵语中是“bhratar”,在拉丁语中是“frater”。尽管琼斯实际上并不是第一个注意到这些相似之处的人,但他关于必然存在共同起源的声明有助于推动比较语言和追溯其关系的运动。
1882 年,雅各布·格林提出了后来被称为格林定律的重要进展。格林今天最为人所知的是格林兄弟中的一位,他们收集并出版了《格林童话》。但除了作为一位民俗学家之外,雅各布·格林还是一位重要的语言学家。
格林表明,随着语言的发展,声音以规则的方式发生变化,这有助于理解语言之间的关系。例如,印欧语中“二”的单词是“dwo”。但是“dwo”是许多单词中的一个,当它传入英语和德语的共同祖先时,它的首字母“d”变成了“t”。后来,“t”音在现代德语的祖先中变成了“ts”。因此,印欧语单词“dwo”在英语中变成了“two”,在现代德语中变成了“zwei”(发音为“tsvai”)。其他以“d”音开头的单词也表现出类似的规律。学者们发现了许多这样的音变模式,每种模式都遵循不同的规则,就像一种语言孕育了另一种语言一样。
除了这些音变之外,语言学家还研究单词是如何构成的,例如英语添加“s”来使单词变成复数的方式。他们还研究单词是如何排列的,例如英语将主语放在动词之前,将动词放在宾语之前的方式。当然,他们还会研究共享的词汇。通过比较不同语言的所有这些特征,语言学家能够绘制出语言如何从一种语言演变而来,并将它们放在显示其关系的家谱树中。
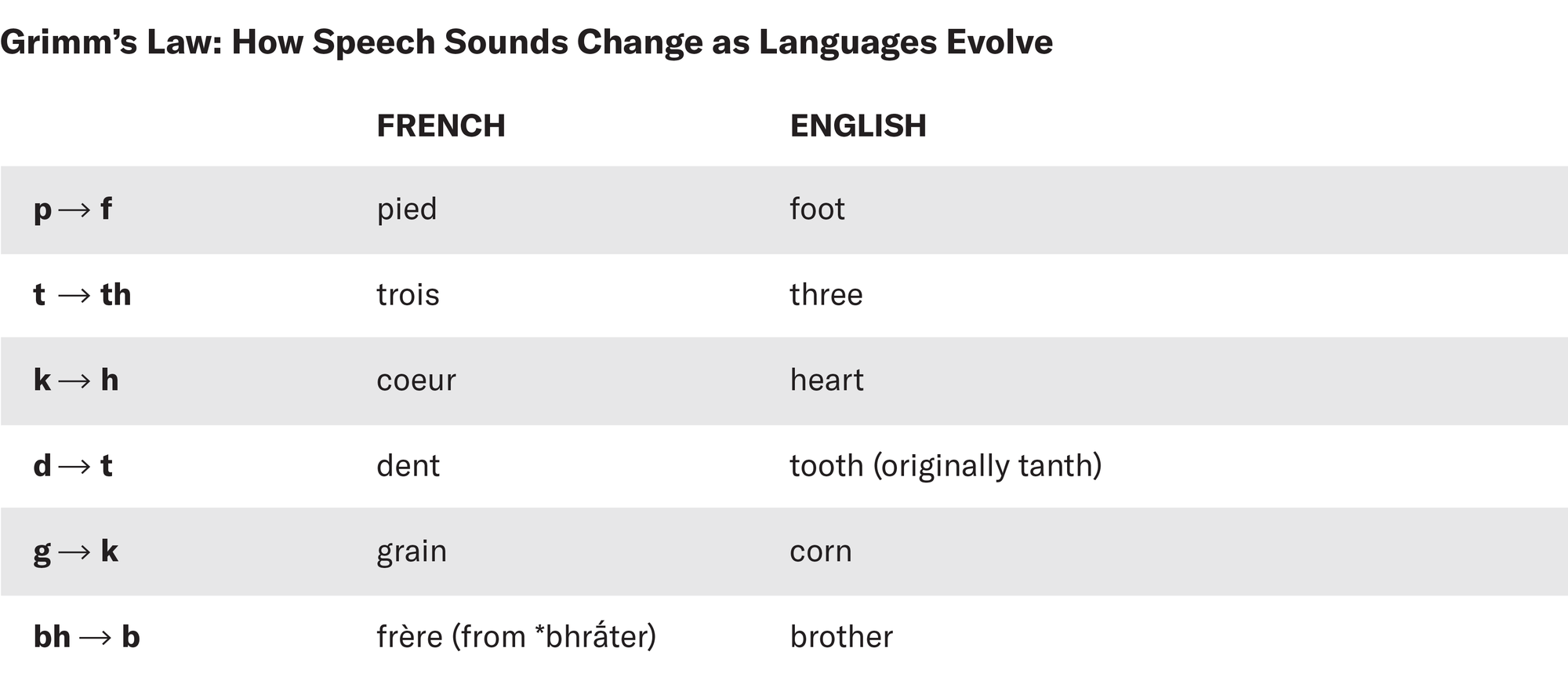
格林定律描述了语言中声音变化的规律性。该图表显示了原始印欧语中的一些声音如何在日耳曼语族语言(如英语)中发生变化,而在非日耳曼语族语言(如法语)中保持不变。来源:Knowable Magazine, 由大众科学重新设计; 资料来源:改编自 L Campbell/The History of Linguistics
今天,语言学家在印欧语系的基本分组以及它们彼此之间的关系上达成了广泛的共识。他们一致认为,最初的语言(他们称之为原始印欧语)分裂成 10 或 11 个主要分支,其中两个分支现已灭绝。
他们通常也同意将语言放在主要分支中的位置。例如,他们知道意大利语分支产生了拉丁语,拉丁语本身又发展成罗曼语族语言,如法语、西班牙语和意大利语。日耳曼语分支发展成包括德语、荷兰语和英语在内的语言。印伊语分支产生了像印地语、孟加拉语、波斯语和库尔德语这样的语言。
祖先的生活方式
通过追溯语言的变化,语言学家推断出了原始印欧语的许多基本特征,包括一些词汇、单词的构成方式以及一些发音方式。许多语言学家认为,他们甚至找到了最初的原始印欧人可能如何生活的线索。
例如,原始印欧语有一个表示车轴的词,两个表示车轮的词,一个表示辕杆的词,以及一个表示“用车运输”的动词。考古学家知道车轮和车轴技术大约在 6000 年前被发明,这表明原始印欧语不可能比这更古老。如果它更古老——换句话说,如果在它有表示车轴和辕杆的词之前就开始分裂成其他语言——那么它的后代语言就不得不发明它们自己的词来表示这些东西。它们使用相同的词这一事实表明,分裂是在这些技术发展之后开始的。
语言中的其他词汇表明,最初的印欧语 speakers 可能熟悉马、牛和绵羊的放牧、乳制品、羊毛、蜂蜜和蜜酒。他们似乎有首领(“reg”这个词给了我们英语单词“regal”)并且可能是父权制的(他们有仅适用于新娘家庭一方的“姻亲”一词,这表明丈夫的家庭被认为是主要的)。
许多语言学家认为,这些词汇描绘了牧民——游牧的牧民——的景象,他们使用马匹和马车。结合基因证据表明,大约在 5000 年前,人们从草原迅速分散到欧洲中部,他们得出结论,印欧语从草原迁移出来,并随着牧民传播开来。
然而,在 1987 年,剑桥考古学家科林·伦福儒拒绝了印欧语的牧民起源说。伦福儒认为,印欧语的巨大传播必然需要比与零星的游牧牧民群体接触所能提供的更大的推动力。伦福儒认为,对于一个单一语言发展壮大到统治从爱尔兰到印度地区的重大转变,你需要更强大的力量。
他在农业的传播中找到了它。简而言之,随着人们开始务农,他们的人口增长速度超过了狩猎采集邻居。随着农业的扩张,语言也随之传播。考古证据表明,农业大约比牧民从草原向外扩张早 3000 年开始从安纳托利亚向外扩张。因此,伦福儒得出结论,农民是印欧语传播的真正动力。到牧民开始迁徙时,他们遇到的农民已经在说印欧语了。
伦福儒在很大程度上驳斥了草原假说所依据的语言学推理。他说,对于车轮、辕杆等词汇的共通性,可以用平行变化来解释,即不同的语言在创造新词时借鉴相同的基本含义。
例如,原始印欧语中“车轮”一词的原始含义似乎类似于圆形或转动。不同的语言可能继承了这种基本含义,并在创建自己的车轮词汇时独立地加以利用。
同样,如果表示辕杆的词“thill”具有更普遍的意义,如棍子或杆子,那么它可能被不止一种语言采用来表示辕杆。
寻求严谨性
诸如此类的论点促使一些语言学家尝试使用更定量的 approach 来重建印欧语的历史。为此,他们借鉴了一种生物学中常用的技术,根据可测量的特征构建进化树。他们的方法称为计算系统发育学,将语言视为类似于生物有机体的进化系统。但是,生物学中的计算系统发育学追踪 DNA 的变化,而语言学中的这项技术追踪的是词汇。具体来说,大多数分析都着眼于不同语言中含义相同的词汇模式,并且可以追溯到相同的原始印欧语词根。这些模式越相似,语言通常就被认为关系越密切。
虽然这听起来可能像语言学家长期以来使用的语言树,但计算系统发育学产生的树远没有那么主观:该方法受严格的算法和明确声明的规则支配。
本质上,计算机程序的工作原理是绘制一棵语言树,并根据所有数据和假设估计其正确的概率。然后,程序对该树进行单次更改,并比较概率分数,保留概率更高的树。这个过程重复进行,有时数百万次,最终产生一组最可能的树。
这些树显示了语言之间的密切关系。为了估计时间——语言起源和彼此分离的时间——研究人员还向计算机程序提供了他们认为不同语言存在的时间的日期,这些日期基于专家的最佳估计。例如,拉丁语大约在 2050 年前存在,古冰岛语大约在 800 年前存在,迈锡尼希腊语大约在 3350 年前存在。计算机程序使用这些锚定日期来创建其时间估计,包括印欧语最终起源的日期。
结果可以与语言使用的历史记录相结合,以帮助弄清它们在地理上如何传播的可能地图。这些日期可以与考古记录和古代人类 DNA 研究相结合,以查看印欧语是否与早期的农业起源或后来的草原起源相符。
矛盾的结果
其中一项此类分析,于 2012 年发表,指出印欧语起源于大约 9000 年前的安纳托利亚,支持了印欧语起源于农民的理论。但仅仅三年后,另一个团队使用了大致相同的数据,得出结论,起源地是仅仅 6000 年前的草原,支持了相反的观点,即牧民是最初的印欧语 speakers。两个团队如何从如此相似的词汇列表中得出如此不同的结论?
赫加蒂深入研究了这个问题,发现问题在于早期分析中使用的数据集,该数据集主要基于 20 世纪 60 年代由耶鲁大学语言学家伊西多尔·戴恩整理的数据集。戴恩的数据集对于戴恩正在进行的研究来说不是问题,但是当用于新的计算技术时,它正在扰乱研究结果。当研究人员感兴趣追踪的每个词根含义都有一个单词时,计算系统发育学效果最佳。但是,例如,“dirty”这个含义在英语中可以有许多同义词,包括“filthy”和“unclean”。戴恩数据集在某些语言的某些单词中包含这样的同义词,但在其他语言中则没有。
赫加蒂意识到,包含任何同义词都会使新的计算技术更难使用该数据集。但是,同义词的数量不一致——某些语言的同义词更多,另一些语言的同义词更少——确实会严重干扰计算。“我说,‘听着,我们必须完全从头开始重新制作这个数据库。我们必须做得更好,’”赫加蒂说。
因此,他和他的同事选择了他们想要追踪的 170 个核心含义——您会期望语言保留的基本词汇,例如表示计数数字、身体部位、颜色以及房屋、山脉、笑和夜晚等事物的词汇。然后,他们召集了一个由 80 多名语言学家组成的团队,让他们确定 161 种印欧语中每种概念的主要词汇。只有该词,没有同义词,进入了分析。
“我们从中制作了一个高度一致的数据库,这是以前从未有人做过的,”赫加蒂说。“我们做了大量的分析,以确保我们选择了最合适的含义。如果你不尽职调查,你的结果将无效。”
当赫加蒂的团队使用这个新数据库重新运行分析时,他们的发现与早期的农民起源理论大致一致,将起源地明确地定位在大约 8000 年前的安纳托利亚。从那里,该语言的一些分支向东移动,产生了包括波斯语和印度斯坦语在内的语言。其他分支向西移动,最终发展成希腊语和阿尔巴尼亚语。
但该分析也承认草原是大多数欧洲语言的次要故乡,发挥了重要作用:在一个分支从安纳托利亚向北迁移到草原之后,它从那里辐射到北欧,产生了日耳曼语、意大利语、盖尔语和其他欧洲语系。
不相信
然而,主流历史语言学家仍然持怀疑态度——对一般的计算系统发育学和特别是新的结果。主要的批评是,该方法主要依赖于词汇,而忽略了词的声音和结构,例如构成单词的词干、前缀和后缀。批评者说,仅凭词义本身并不能提供足够的信息来得出确凿的结论,无论计算多么复杂。
托马斯·奥兰德是哥本哈根大学的历史语言学家,他说,依赖相关词汇的问题在于,语言一直在互相借用词汇。因此,仅仅看到两种语言之间存在共同的词汇,并不意味着这两种语言来自同一个母语。例如,英语 speakers 现在使用“sushi”这个词,并不意味着英语和日语是相关的语言。
相反,大多数语言学家倾向于信任音变——例如“dwo”– “two” – “zwei”的变化——以及词汇结构的相似性,这可以表明它们起源于哪种语言。词义也可以是这种混合的一部分,但它们不能单独做到这一点,奥兰德说。
赫加蒂的树也有其他问题。例如,它显示凯尔特语与日耳曼语密切相关。但奥兰德说,大多数历史语言学家认为凯尔特语与意大利语更密切相关。
“这又是一件令人惊讶的事情,”奥兰德说。“我认为‘令人惊讶’可以翻译成‘这可能意味着他们的方法是错误的。’”
奥兰德认为,更可能的情况是,凯尔特语和日耳曼语分支长期以来密切共存,并互相借用词汇。他说,仅基于共享词义的分析显示它们之间的关系比实际更密切。
剑桥大学的语言学家詹姆斯·克拉克森也认为原始印欧语的早期日期以及树的其他细节令人难以置信。但他认为计算系统发育学值得追求。他说,如果说还有其他的话,那么最近的研究创建了一个非常高质量的新数据集,这将对一般的历史语言学家在寻求解决他们领域中许多悬而未决的问题时非常重要。
与此同时,计算系统发育学的倡导者可能会继续推广他们的方法,并寻求更广泛学科的认可。赫加蒂认为,随着主流语言学家越来越适应这种方法及其使用的高质量数据,他们可能会更多地倾听它。
克拉克森表示,他愿意被说服。“这是一个发展中的领域,值得关注,”他说。
本文最初发表于Knowable Magazine,这是来自 Annual Reviews 的一项独立新闻事业。注册新闻通讯。