
考虑一下安迪,他担心在2020年感染新冠病毒。由于无法阅读所有关于新冠病毒的文章,他依靠信任的朋友提供建议。当一位朋友在Facebook上评论说对疫情的恐惧被夸大了时,安迪起初不以为然。但随后,他工作的酒店关门了,他的工作岌岌可危,安迪开始怀疑病毒的威胁到底有多严重。毕竟,他认识的人中没有人因此丧生。一位同事发布了一篇文章,称新冠“恐慌”是由大型制药公司与腐败政客勾结制造的,这与安迪对政府的不信任不谋而合。他的网络搜索很快将他带到一些文章,声称新冠病毒并不比流感更严重。安迪加入了一个由失业或担心失业的人组成的在线群组,很快发现自己像他们中的许多人一样问道:“什么疫情?” 当他得知几位新朋友计划参加一次要求结束封锁的集会时,他决定加入他们。包括他在内,几乎没有人在这场大规模抗议活动中戴口罩。当他的姐姐询问集会时,安迪分享了他现在已成为他身份一部分的信念:新冠病毒是一场骗局。
这个例子说明了一个认知偏差的雷区。我们更喜欢来自我们信任的人、我们群体内部的信息。我们关注风险信息,也更可能分享风险信息——对安迪来说,是失去工作的风险。我们会搜索并记住与我们已知和理解的事物相符的信息。这些偏差是我们进化过去的产物,在数万年里,它们对我们很有帮助。那些行为符合这些偏差的人——例如,远离有人说有毒蛇的杂草丛生的池塘边——比那些不这样做的人更有可能生存下来。
然而,现代技术正在以有害的方式放大这些偏差。搜索引擎将安迪导向加剧他怀疑的网站,社交媒体将他与志同道合的人联系起来,加剧了他的恐惧。更糟糕的是,机器人——模仿人类的自动化社交媒体账户——使误入歧途或怀有恶意的行为者能够利用他的弱点。
关于支持科学新闻
如果您喜欢这篇文章,请考虑支持我们屡获殊荣的新闻事业,方式是 订阅。通过购买订阅,您正在帮助确保有关当今塑造我们世界的发现和想法的具有影响力的故事的未来。
在线信息的激增加剧了这个问题。查看和制作博客、视频、推文和其他称为“迷因”的信息单元变得如此廉价和容易,以至于信息市场充斥着信息。由于无法处理所有这些材料,我们让认知偏差决定我们应该关注什么。这些心理捷径在有害的程度上影响着我们搜索、理解、记住和重复哪些信息。
理解这些认知漏洞以及算法如何使用或操纵它们已变得迫在眉睫。在英国华威大学和印第安纳大学布卢明顿分校的社交媒体观察站 (OSoMe,发音为“awesome”),我们的团队正在使用认知实验、模拟、数据挖掘和人工智能来理解社交媒体用户的认知漏洞。在华威大学进行的关于信息进化的心理学研究的见解为印第安纳大学开发的计算机模型提供了信息,反之亦然。我们还在开发分析和机器学习辅助工具,以对抗社交媒体操纵。记者、公民社会组织和个人已经在使用其中一些工具来检测虚假行为者,绘制虚假叙事的传播图,并培养新闻素养。
信息过载
信息的过剩引发了对人们注意力的激烈竞争。正如诺贝尔经济学奖得主和心理学家赫伯特·A·西蒙所指出的,“信息消耗的东西显而易见:它消耗了接收者的注意力。” 所谓注意力经济的首要后果之一是高质量信息的流失。OSoMe团队通过一组简单的模拟演示了这一结果。它将社交媒体用户(如安迪)称为代理,表示为在线熟人网络中的节点。在模拟的每个时间步,代理可以创建迷因,也可以转发在新闻提要中看到的迷因。为了模拟有限的注意力,代理只能查看新闻提要顶部附近的有限数量的项目。
莉莲·翁(现就职于OpenAI)和OSoMe的研究人员发现,在多次时间步运行此模拟后,随着代理的注意力变得越来越有限,迷因的传播开始反映实际社交媒体的幂律分布:迷因被分享给定次数的概率大约是该次数的倒幂。例如,迷因被分享三次的可能性大约是其被分享一次的九分之一。
迷因的这种赢家通吃的流行模式(大多数迷因几乎无人注意,而少数迷因却广泛传播)无法用其中一些迷因更吸引人或在某种程度上更有价值来解释:这个模拟世界中的迷因没有内在质量。病毒式传播纯粹是由注意力有限的代理社交网络中信息扩散的统计结果造成的。即使代理优先分享高质量的迷因,当时在OSoMe的研究员邱晓燕也观察到,在分享最多的迷因的整体质量方面几乎没有改善。我们的模型揭示,即使我们想看到和分享高质量的信息,我们无法查看新闻提要中的所有内容也必然会导致我们分享部分或完全不真实的内容。
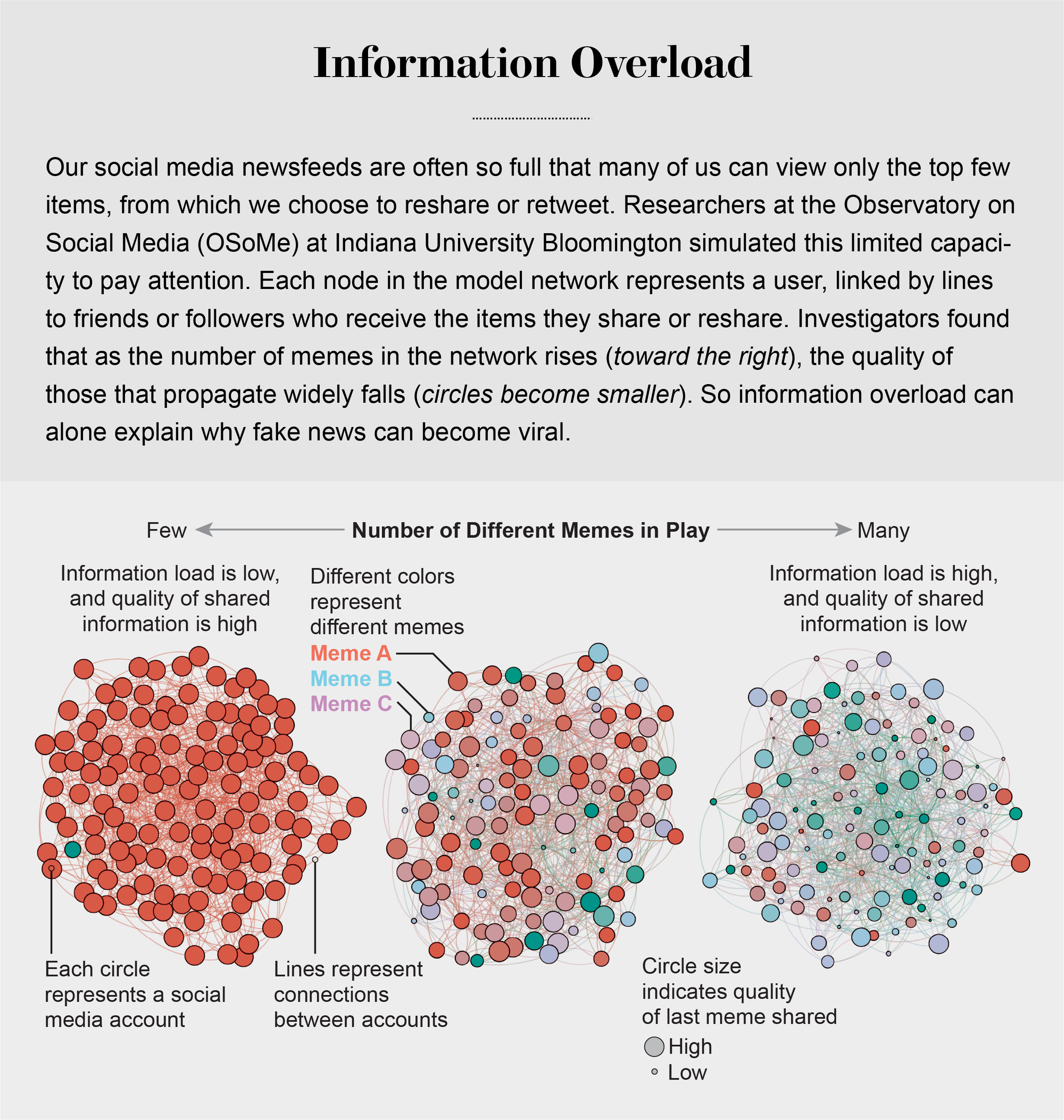
来源:“个人注意力有限和低质量信息的在线病毒式传播”,作者:邱晓燕等,发表于《自然人类行为》,第1卷,2017年6月
认知偏差大大加剧了这个问题。在1932年进行的一系列开创性研究中,心理学家弗雷德里克·巴特利特给志愿者讲述了一个关于年轻人的美洲原住民传说,这个年轻人听到战争的呼喊声,追逐着它们,进入了一场梦幻般的战斗,最终导致了他的真正死亡。巴特利特要求这些非美洲原住民志愿者在越来越长的时间间隔(从几分钟到几年后)回忆起这个相当令人困惑的故事。他发现,随着时间的推移,记忆者倾向于扭曲故事中不熟悉的文化部分,使它们要么被记忆遗忘,要么转化为更熟悉的事物。我们现在知道,我们的大脑一直都在这样做:它们调整我们对新信息的理解,使其与我们已知的信息相符。这种所谓的证实偏差的一个结果是,人们经常寻找、回忆和理解最能证实他们已经相信的信息。
这种倾向极其难以纠正。实验一致表明,即使人们遇到包含来自不同视角的观点的平衡信息,他们也倾向于为自己已经相信的事物找到佐证。当对气候变化等情绪化问题持有不同信念的人们看到关于这些问题的相同信息时,他们会更加坚持自己最初的立场。
更糟糕的是,搜索引擎和社交媒体平台会根据他们掌握的大量用户过去偏好的数据提供个性化推荐。他们优先推送我们最有可能同意的信息(无论多么边缘化),并将我们屏蔽在可能改变我们想法的信息之外。这使我们很容易成为两极分化的目标。尼尔·格林伯格和他在东北大学的同事在2019年表明,美国的保守派更容易接受错误信息。但我们自己对Twitter上低质量信息消费的分析表明,这种脆弱性适用于政治光谱的两端,没有人能完全避免它。即使我们检测在线操纵的能力也受到我们的政治偏见的影响,尽管并非对称地:共和党用户更可能将宣传保守派观点的机器人误认为是人类,而民主党人更可能将保守派人类用户误认为是机器人。
社会群体行为
2019年8月在纽约市,人们开始逃离听起来像枪声的声音。其他人也跟着跑,有些人喊着“枪手!” 后来他们才知道,爆炸声来自摩托车回火。在这种情况下,先跑为上,事后诸葛亮可能更有利。在缺乏明确信号的情况下,我们的大脑会利用关于人群的信息来推断适当的行动,类似于鱼群和鸟群的行为。
这种社会顺从性很普遍。在2006年马修·萨尔加尼克(当时在哥伦比亚大学)和他的同事进行的一项引人入胜的涉及14,000名网络志愿者的研究中,他们发现,当人们可以看到其他人下载的音乐时,他们最终也会下载类似的歌曲。此外,当人们被隔离成“社交”群体时,他们可以看到圈子里其他人的偏好,但对圈外人一无所知,各个群体的选择迅速出现分歧。但是,在“非社交”群体中,没有人知道其他人的选择,偏好保持相对稳定。换句话说,社会群体创造了一种强大的趋同压力,它可以克服个人偏好,并且通过放大随机的早期差异,它可以导致隔离的群体走向极端。
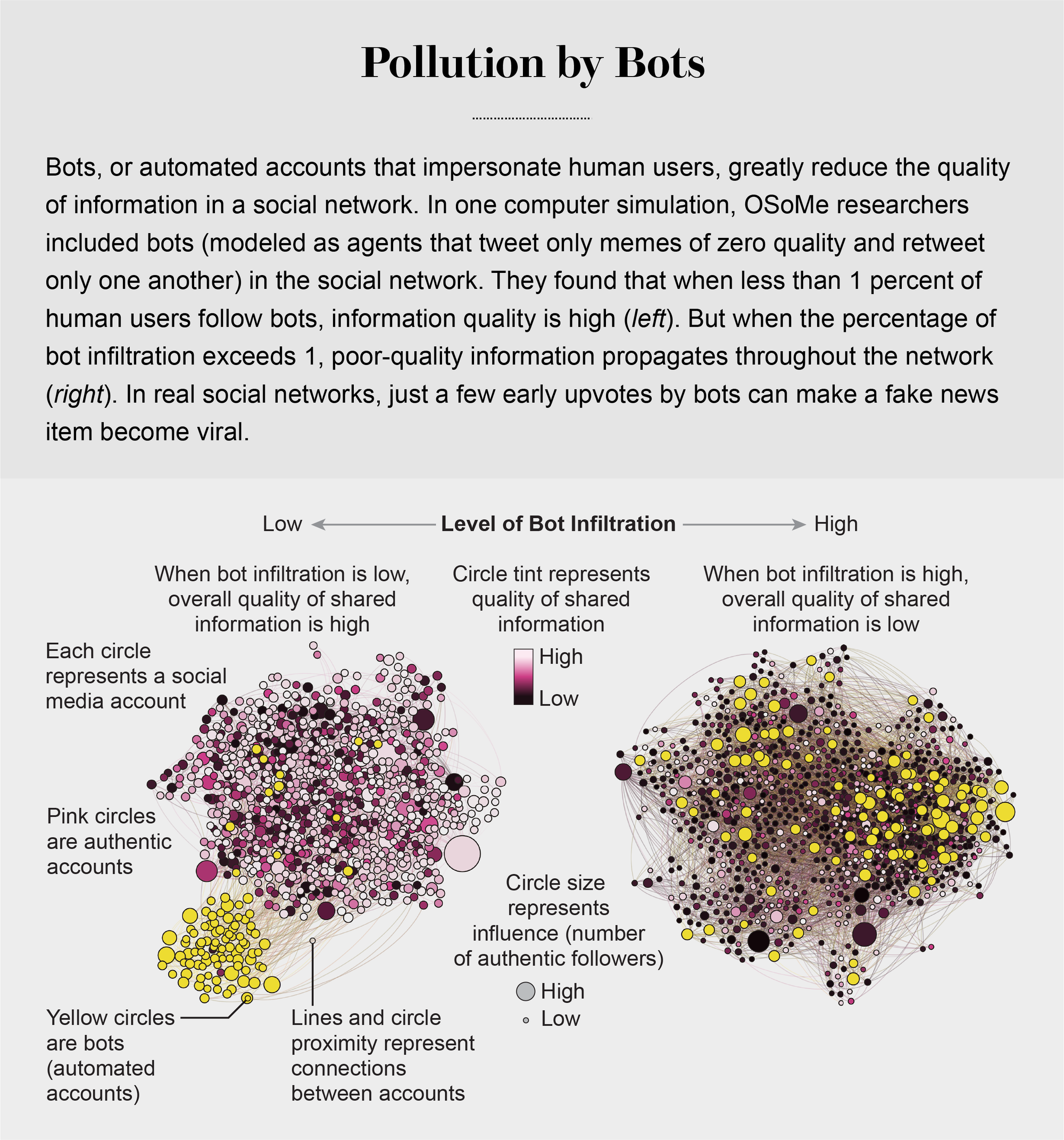
图片来源:Filippo Menczer
社交媒体遵循类似的动态。我们将流行度与质量混淆,最终复制我们观察到的行为。丹麦技术大学的比雅克·蒙斯特德和他的同事在Twitter上进行的实验表明,信息是通过“复杂传染”传播的:当我们反复接触到一个想法时,通常来自多个来源,我们就更有可能采纳并转发它。心理学家称之为“单纯曝光效应”进一步放大了这种社会偏见:当人们反复接触相同的刺激(例如某些面孔)时,他们会比那些他们接触较少的刺激更喜欢这些刺激。
这些偏见转化为一种不可抗拒的冲动,即关注正在疯传的信息——如果其他所有人都在谈论它,那它一定是重要的。除了向我们展示符合我们观点的项目外,Facebook、Twitter、YouTube 和 Instagram 等社交媒体平台还将热门内容放在我们屏幕的顶部,并向我们展示有多少人点赞和分享了某些内容。很少有人意识到这些提示并未提供对质量的独立评估。
事实上,为社交媒体上的迷因排名设计算法的程序员假设“群体智慧”将迅速识别出高质量的项目;他们使用流行度作为质量的替代指标。我们对大量关于点击次数的匿名数据的分析表明,所有平台(社交媒体、搜索引擎和新闻网站)都优先推送来自一小部分热门来源的信息。
为了理解原因,我们模拟了他们如何在排名中结合质量和流行度信号。在这个模型中,注意力有限的代理(那些只看到新闻提要顶部给定数量的项目的人)也更可能点击平台排名前列的迷因。每个项目都具有内在质量,以及由其被点击次数决定的流行度级别。另一个变量跟踪排名在多大程度上依赖于流行度而不是质量。该模型的模拟表明,即使在没有人类偏见的情况下,这种算法偏差通常也会抑制迷因的质量。即使我们想分享最好的信息,算法最终也会误导我们。
回音室
我们大多数人都不相信自己随波逐流。但我们的证实偏差导致我们追随与我们相似的人,这种动态有时被称为同质性——志同道合的人相互联系的倾向。社交媒体通过允许用户通过关注、取消关注等方式改变其社交网络结构来放大同质性。结果是,人们被隔离成大型、密集且越来越被误导的社区,通常被称为回音室。
在OSoMe,我们通过另一个模拟EchoDemo探索了在线回音室的出现。在这个模型中,每个代理都有一个政治观点,用从-1(比如,自由派)到+1(保守派)的数字表示。这些倾向反映在代理的帖子中。代理也受他们在新闻提要中看到的观点的影响,他们可以取消关注意见不同意的用户。从随机的初始网络和观点开始,我们发现社会影响和取消关注的结合大大加速了两极分化和隔离社区的形成。
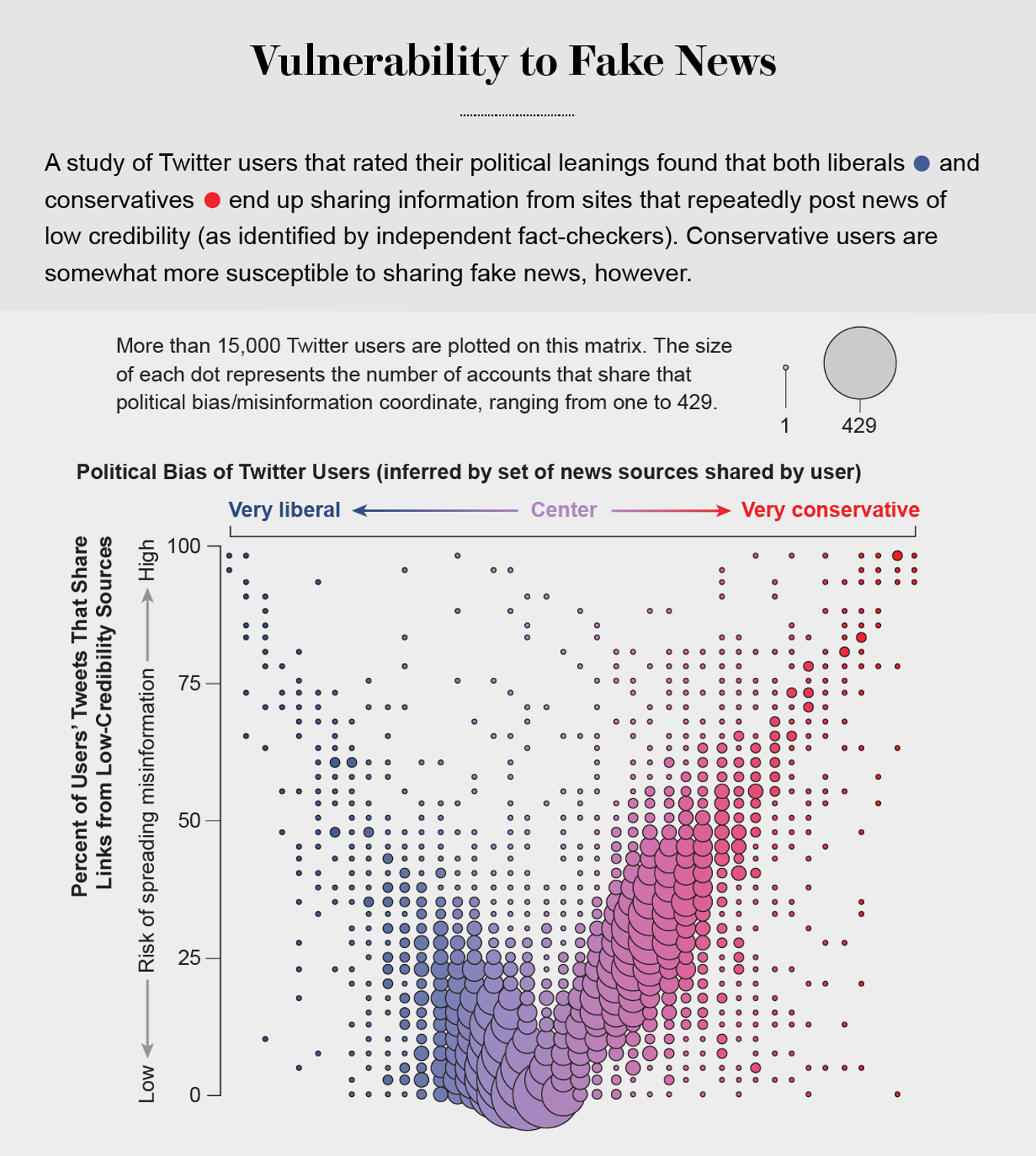
图片来源:Jen Christiansen;资料来源:Dimitar Nikolov 和 Filippo Menczer (数据)
事实上,Twitter上的政治回音室非常极端,以至于可以高精度预测单个用户的政治倾向:你的观点与你的大多数联系人相同。这种分室结构有效地在社区内传播信息,同时将该社区与其他群体隔离开来。2014年,我们的研究小组成为一场虚假信息宣传活动的目标,该活动声称我们是出于政治动机压制言论自由的一部分。这种虚假指控主要在保守派回音室中病毒式传播,而事实核查员的反驳文章主要出现在自由派社区中。可悲的是,虚假新闻项目与其事实核查报告的这种隔离是常态。
社交媒体也会增加负面情绪。在2018年的一项实验室研究中,现就职于牛津大学的罗伯特·贾吉洛和我们中的一位(希尔斯)发现,社会共享的信息不仅会增强偏见,而且会变得更难以纠正。我们调查了信息如何在所谓的社会扩散链中人与人之间传递。在实验中,链条中的第一个人阅读了一组关于核能或食品添加剂的文章。这些文章的设计是平衡的,包含尽可能多的正面信息(例如,关于减少碳污染或更持久的食物)和负面信息(例如,熔毁风险或可能对健康造成的危害)。
社会扩散链中的第一个人将文章告诉下一个人,第二个人告诉第三个人,依此类推。我们观察到,随着负面信息沿着链条传递,负面信息的量总体增加——这被称为风险的社会放大。此外,澳大利亚新南威尔士大学的丹妮尔·J·纳瓦罗和她的同事的工作发现,社会扩散链中的信息最容易被偏见最极端的人扭曲。
更糟糕的是,社会扩散也使负面信息更“粘性”。当贾吉洛和希尔斯随后让社会扩散链中的人们接触到原始的平衡信息时——即链条中的第一个人看到的新闻——平衡信息对减少个人的负面态度几乎没有作用。通过人际传播的信息不仅变得更加负面,而且更难以更新。
艾米利奥·费拉拉和泽尧·杨(当时都是OSoMe的研究人员)在2015年的一项研究中分析了关于Twitter上这种“情绪传染”的经验数据,发现过度接触负面内容的人倾向于分享负面帖子,而过度接触正面内容的人倾向于分享更多正面帖子。由于负面内容比正面内容传播得更快,因此很容易通过创建引发恐惧和焦虑等负面反应的叙事来操纵情绪。费拉拉(现就职于南加州大学)和他在意大利布鲁诺·克 Kessler基金会的同事已经表明,在西班牙2017年关于加泰罗尼亚独立的公投期间,社交机器人被用来转发暴力和煽动性叙事,增加了它们的曝光率并加剧了社会冲突。
机器人的崛起
社交机器人进一步损害了信息质量,社交机器人可以利用我们所有的认知漏洞。机器人很容易创建。社交媒体平台提供所谓的应用程序编程接口,这使得单个行为者可以非常轻松地设置和控制数千个机器人。但是,放大一条消息,即使只是在Reddit等社交媒体平台上获得机器人的一些早期赞成票,也可能对帖子随后的受欢迎程度产生巨大影响。
在OSoMe,我们开发了机器学习算法来检测社交机器人。其中之一是Botometer,这是一个公共工具,它从给定的Twitter帐户中提取1,200个特征,以描述其个人资料、朋友、社交网络结构、时间活动模式、语言和其他特征。该程序将这些特征与先前识别的数万个机器人的特征进行比较,从而为Twitter帐户的自动化使用可能性评分。
2017年,我们估计,高达15%的活跃Twitter帐户是机器人——并且它们在2016年美国大选期间的错误信息传播中发挥了关键作用。在虚假新闻文章发布后的几秒钟内——例如一篇声称克林顿竞选团队参与了神秘仪式的文章——许多机器人就会在Twitter上发布该文章,而受内容表面上的受欢迎程度所迷惑的人类会转发它。
机器人还通过假装代表我们群体内部的人来影响我们。一个机器人只需要关注、点赞和转发在线社区中的某个人,就可以迅速渗透到该社区中。北京师范大学的楼晓丹与OSoMe合作开发了另一个模型,其中一些代理是机器人,它们渗透到社交网络中并分享具有欺骗性的低质量内容——想想点击诱饵。模型中的一个参数描述了真实代理关注机器人的概率——为了这个模型的目的,我们将机器人定义为生成零质量迷因并且只相互转发的代理。我们的模拟表明,这些机器人只需渗透到网络的一小部分,就可以有效地抑制整个生态系统的信息质量。机器人还可以通过建议关注其他不真实的帐户来加速回音室的形成,这种技术被称为创建“关注列车”。
一些操纵者通过独立的虚假新闻网站和机器人来玩弄分裂的两面,从而推动政治两极分化或通过广告获利。在OSoMe,我们发现了一个Twitter上的不真实帐户网络,这些帐户都由同一个实体协调。有些假装是特朗普“让美国再次伟大”美国总统竞选活动的支持者,而另一些则冒充特朗普“抵抗者”,他们都要求政治捐款。此类行动放大了利用证实偏见的内容,并加速了两极分化的回音室的形成。
遏制在线操纵
了解我们的认知偏差以及算法和机器人如何利用它们,使我们能够更好地防范操纵。OSoMe制作了许多工具,以帮助人们了解自己的弱点以及社交媒体平台的弱点。其中一个是名为Fakey的移动应用程序,它可以帮助用户学习如何识别错误信息。该游戏模拟社交媒体新闻提要,显示来自低可信度和高可信度来源的真实文章。用户必须决定他们可以或不应该分享什么,以及要对什么进行事实核查。来自Fakey的数据分析证实了在线社会群体行为的普遍性:当用户认为许多其他人分享了低可信度的文章时,他们更有可能分享这些文章。
另一个可供公众使用的程序名为Hoaxy,它显示了任何现有的迷因如何在Twitter上传播。在这个可视化中,节点代表真实的Twitter帐户,链接描述了转发、引用、提及和回复如何将迷因从一个帐户传播到另一个帐户。每个节点都有一个颜色,代表其来自Botometer的分数,这使用户可以看到机器人放大错误信息的规模。调查记者已经使用这些工具来揭露错误信息宣传活动的根源,例如在美国推动“披萨门”阴谋论的宣传活动。它们还有助于检测2018年美国中期选举期间机器人驱动的选民压制行动。然而,操纵正变得越来越难以发现,因为机器学习算法在模仿人类行为方面变得越来越出色。
除了传播虚假新闻外,错误信息宣传活动还可以转移人们对其他更严重问题的注意力。为了打击这种操纵,我们开发了一种名为BotSlayer的软件工具。它提取用户希望研究的主题的推文中共现的主题标签、链接、帐户和其他特征。对于每个实体,BotSlayer会跟踪推文、发布推文的帐户及其机器人评分,以标记正在趋势化并且可能被机器人或协同帐户放大的实体。目标是使记者、公民社会组织和政治候选人能够实时发现和跟踪不真实的影响力宣传活动。
这些程序化工具是重要的辅助工具,但制度变革对于遏制虚假新闻的扩散也是必要的。教育可以提供帮助,尽管它不太可能涵盖人们被误导的所有主题。一些政府和社交媒体平台也在尝试打击在线操纵和虚假新闻。但是,谁来决定什么是虚假的或具有操纵性的,什么不是?信息可以附带警告标签,例如Facebook和Twitter提供的标签,但是应用这些标签的人可以信任吗?这种措施可能有意或无意地压制对健全的民主至关重要的言论自由的风险是真实存在的。在全球范围内具有影响力的社交媒体平台以及与政府的密切联系进一步使可能性复杂化。
最好的想法之一可能是使创建和共享低质量信息更加困难。这可能涉及通过迫使人们付费共享或接收信息来增加摩擦。付款可以是时间、脑力劳动(如谜题)或订阅或使用费的形式。自动化发布应像广告一样对待。一些平台已经在使用摩擦,形式为CAPTCHA和电话确认来访问帐户。Twitter已对自动化发布施加了限制。可以扩大这些努力,以逐步将在线共享激励转向对消费者有价值的信息。
自由沟通并非免费。通过降低信息的成本,我们降低了信息的价值,并招致了信息的掺假。为了恢复我们信息生态系统的健康,我们必须了解我们不堪重负的大脑的脆弱性,以及如何利用信息经济学来保护我们免受误导。