
以下文章经允许转载自The Conversation,这是一个报道最新研究的在线出版物。
如果你像大多数美国人那样从社交媒体获取新闻,你每天都会接触到大量的恶作剧、谣言、阴谋论和误导性新闻。当这些信息与来自可靠来源的真实信息混杂在一起时,真相就很难辨别了。
关于支持科学新闻
如果您喜欢这篇文章,请考虑通过以下方式支持我们屡获殊荣的新闻报道: 订阅。通过购买订阅,您正在帮助确保未来能够发布关于塑造我们当今世界的发现和想法的有影响力的故事。
事实上,我的研究团队对哥伦比亚大学的Emergent谣言跟踪器的数据分析表明,这种虚假信息像可靠信息一样容易在网上疯传。
许多人都在问,这种数字虚假信息的冲击是否影响了2016年美国大选的结果。事实是我们不知道,尽管根据过去的分析和其他国家的报道,有理由相信这完全有可能。每一条虚假信息都会影响我们观点的形成。总的来说,危害可能是非常真实的:如果人们可以被欺骗到危及我们孩子生命的地步,就像他们选择不接种疫苗时那样,为什么不能危害我们的民主呢?
作为一名研究社交媒体虚假信息传播的研究人员,我知道限制新闻造假者销售广告的能力是朝着正确方向迈出的一步,正如谷歌和脸书最近宣布的那样。但这并不能遏制政治动机驱动的滥用行为。
利用社交媒体
大约10年前,我的同事和我进行了一项实验,其中我们了解到,72%的大学生信任看起来来自朋友的链接——甚至到了在网络钓鱼网站上输入个人登录信息的程度。这种普遍存在的漏洞表明了另一种形式的恶意操纵:人们也可能会相信他们点击来自社交联系人的链接时收到的虚假信息。
为了探索这个想法,我创建了一个虚假的网页,其中包含随机的、计算机生成的八卦新闻——比如“名人X和名人Y被抓到在床上!”访问该网站并搜索名字的访问者会触发脚本自动捏造关于这个人的故事。我在网站上包含了一个免责声明,说明该网站包含毫无意义的文本和编造的“事实”。我还在这页面上放置了广告。月底,我收到了一张来自广告的收入支票。这就是我的证明:虚假新闻可以通过用谎言污染互联网来赚钱。
可悲的是,我并不是唯一有这种想法的人。十年后,我们有了一个虚假新闻产业和数字虚假信息。诱点击网站制造恶作剧以从广告中赚钱,而所谓的极端党派网站发布和传播谣言和阴谋论以影响公众舆论。
这个产业得益于创建社交机器人的便利,这些机器人是由软件控制的虚假帐户,看起来像真人,因此可以产生真正的影响。我在实验室的研究中发现了许多虚假的基层运动的例子,也称为政治伪草根运动。
作为回应,我们开发了BotOrNot工具来检测社交机器人。它并不完美,但是足够准确,可以揭露英国脱欧和反疫苗运动中的劝导活动。通过使用 BotOrNot,我们的同事发现,关于2016年大选的很大一部分在线聊天是由机器人生成的。
创建信息泡沫
由于一系列复杂的社会、认知、经济和算法偏差,我们人类很容易受到数字虚假信息的操纵。其中一些偏差的出现是有充分理由的:信任来自我们社交圈的信号,拒绝与我们的经验相矛盾的信息,这在我们人类适应躲避捕食者时对我们很有帮助。但在当今萎缩的在线网络中,与地球另一端的阴谋论者建立社交网络联系无助于形成我的观点。
复制我们的朋友并取消关注那些持有不同意见的人,会给我们带来如此两极分化的回音室,以至于研究人员可以通过查看你的朋友来高精度地判断你是自由主义者还是保守主义者。网络结构是如此密集,以至于任何虚假信息几乎都会在一个群体内立即传播,并且如此隔离,以至于无法到达另一个群体。
在我们的泡沫中,我们有选择地接触与我们信仰一致的信息。这是最大限度提高参与度的理想场景,但对培养健康的怀疑主义不利。确认偏误导致我们分享一个标题,而甚至没有阅读文章。
当我们自己的研究项目成为2014年美国中期选举前夕恶毒的虚假信息运动的主题时,我们的实验室亲自吸取了教训。当我们调查发生了什么时,我们发现关于我们研究的虚假新闻主要由一个党派回音室中的推特用户分享,这是一个庞大且同质的政治活跃用户群体。这些人很快就转发了信息,并且对揭穿信息毫不在意。
病毒式传播的必然性
我们的研究表明,考虑到我们社交网络的结构和我们有限的注意力,一些模因,不管它们的质量如何,都不可避免地会在网上疯传。即使个人倾向于分享更高质量的信息,整个网络也不能有效地辨别可靠信息和虚假信息。这有助于解释我们在野外观察到的所有病毒式恶作剧。
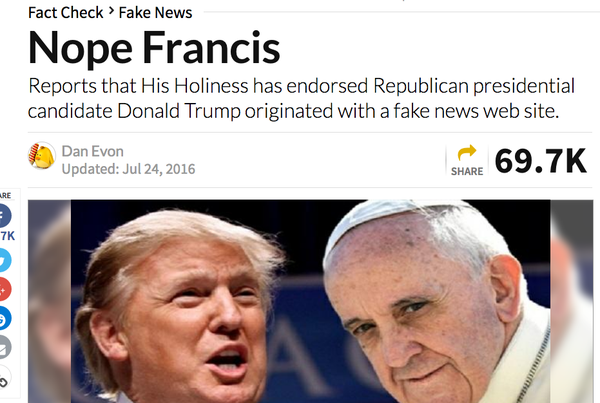
注意力经济负责其余的事情:如果我们关注某个话题,就会产生更多关于该话题的信息。制造虚假信息并将其冒充为事实比报道真实真相更便宜。而且捏造信息可以针对每个群体进行定制:保守派阅读到教皇认可了特朗普,自由派阅读到他认可了克林顿。他都没有这样做。
受算法的支配
由于我们无法关注我们推送中的所有帖子,算法决定了我们看到什么和看不到什么。当今社交媒体平台使用的算法旨在优先考虑引人入胜的帖子——我们可能会点击、反应和分享的帖子。但最近的一项分析发现,故意误导性的页面至少获得了与真实新闻一样多的在线分享和反应。
这种算法对参与度而不是真相的偏见加强了我们的社会和认知偏见。因此,当我们在社交媒体上点击分享的链接时,我们倾向于访问比我们进行搜索并访问顶部结果时更小、更同质化的来源集。
现有的研究表明,处于回音室可能会使人们更容易接受未经证实的谣言。但我们需要更多地了解不同的人对同一个恶作剧的反应:有些人会立即分享,有些人会先进行事实核查。
我们正在模拟一个社交网络来研究这种分享和事实核查之间的竞争。我们希望帮助理清关于事实核查何时有助于阻止恶作剧传播以及何时没有帮助的相互矛盾的证据。我们的初步结果表明,恶作剧信徒的社区越隔离,恶作剧的持续时间就越长。同样,这不仅仅关乎恶作剧本身,还关乎网络。
很多人都在试图弄清楚该如何解决这一切。根据马克·扎克伯格最新的公告,脸书团队正在测试潜在的方案。一群大学生提出了一种简单地将共享链接标记为“已验证”或未验证的方法。
一些解决方案至少目前仍然遥不可及。例如,我们还不能教会人工智能系统如何辨别真假。但我们可以告诉排名算法,优先考虑更可靠的来源。
研究虚假新闻的传播
如果我们能更好地了解虚假信息是如何传播的,我们就能更有效地打击假新闻。例如,如果机器人是许多谎言的始作俑者,我们可以将注意力集中在检测它们上。或者,如果问题出在回音室效应上,或许我们可以设计不排除不同观点的推荐系统。
为此,我们的实验室正在构建一个名为Hoaxy的平台,以跟踪和可视化社交媒体上未经证实的说法及其相应的事实核查的传播。这将为我们提供真实世界的数据,我们可以利用这些数据来构建我们的模拟社交网络。然后,我们可以测试对抗假新闻的可能方法。
Hoaxy也可能向人们展示他们的观点是多么容易被在线信息操纵——甚至展示我们中的一些人有多么可能在网上分享谎言。Hoaxy将加入我们社交媒体观察站中的一套工具,该工具允许任何人查看模因在Twitter上的传播情况。将这些工具与人工事实核查员和社交媒体平台连接起来,可以更容易地最大限度地减少重复工作并互相支持。
我们必须投入资源研究这种现象。我们需要各方共同努力:计算机科学家、社会科学家、经济学家、记者和行业合作伙伴必须协同工作,坚决抵制虚假信息的传播。
本文最初发表于The Conversation。请阅读原文。