研究人员正在滥用 ChatGPT 和其他人工智能聊天机器人来撰写科学文献。至少,这是某些科学家提出的新担忧,他们指出,已发表论文中出现的可疑 AI 隐语急剧增加。
其中一些迹象——例如最近发表在爱思唯尔出版的期刊Surfaces and Interfaces上的一篇论文中无意中包含的“当然,这是您主题的可能介绍”——是相当明显的证据,表明科学家使用了被称为大型语言模型 (LLM) 的 AI 聊天机器人。但科学诚信顾问伊丽莎白·比克说,“这可能只是冰山一角”。(爱思唯尔的一位代表告诉大众科学,该出版商对这种情况感到遗憾,并且正在调查这种情况是如何“溜过”稿件评估过程的。)在大多数其他情况下,AI 的参与并不那么明确,而且自动 AI 文本检测器是分析论文的不可靠的工具。
然而,来自多个领域的研究人员已经确定了一些关键词和短语(例如“复杂且多方面”),这些词语和短语在 AI 生成的句子中比在典型的人类写作中更频繁地出现。“当你长期关注这些东西时,你就会对这种风格有所感觉,”伦敦大学学院的图书管理员和研究员安德鲁·格雷说。
关于支持科学新闻报道
如果您喜欢这篇文章,请考虑通过以下方式支持我们屡获殊荣的新闻报道 订阅。通过购买订阅,您正在帮助确保有关塑造我们当今世界的发现和想法的具有影响力的故事的未来。
LLM 旨在生成文本——但它们产生的内容可能在事实上准确,也可能不准确。“问题在于这些工具还不够好,无法信任,”比克说。它们屈服于计算机科学家所谓的幻觉:简而言之,它们会编造东西。“具体来说,对于科学论文,”比克指出,AI“将生成不存在的引文参考文献。” 因此,如果科学家对 LLM 过度信任,研究作者就有可能将 AI 编造的缺陷插入到他们的工作中,从而在已经混乱的科学出版现实中混入更多潜在的错误。
格雷最近使用 Dimensions(一个数据分析平台,其开发者表示该平台跟踪超过 1.4 亿篇全球论文)在科学论文中搜索 AI 流行语。他搜索了聊天机器人过度使用的词语,例如“错综复杂”、“细致”和“值得称赞”。他说,这些指示词比任何笨拙的作者可能复制到论文中的“泄露”AI 短语更能让人了解问题的规模。根据格雷的分析(该分析已在预印本服务器 arXiv.org 上发布,但尚未经过同行评审),至少有 60,000 篇论文(略多于去年全球发表的所有科学文章的 1%)可能使用了 LLM。其他专门关注科学子领域的研究表明,对 LLM 的依赖程度更高。其中一项调查发现,高达 17.5% 的最新计算机科学论文表现出 AI 写作的迹象。
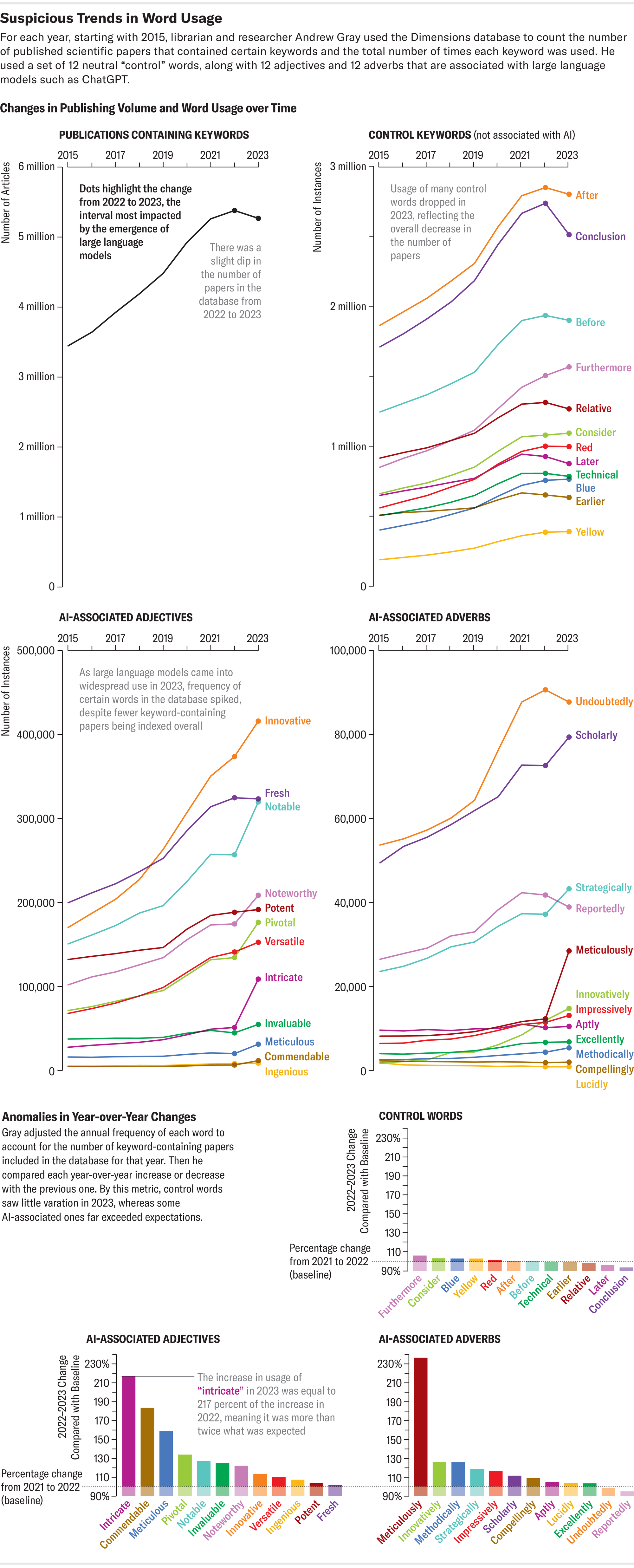
阿曼达·蒙塔内斯;来源:安德鲁·格雷
大众科学自身使用 Dimensions 和其他几个科学出版物数据库(包括 Google Scholar、Scopus、PubMed、OpenAlex 和 Internet Archive Scholar)进行的搜索也支持了这些发现。这项搜索旨在寻找可以表明 LLM 参与学术论文文本制作的迹象——通过 ChatGPT 和其他 AI 模型通常附加的短语(例如“截至我上次知识更新”)的流行程度来衡量。2020 年,这个短语在调查中使用的四个主要论文分析平台跟踪的结果中仅出现一次。但在 2022 年,它出现了 136 次。不过,这种方法存在一些局限性:它无法过滤掉可能代表 AI 模型自身研究而不是 AI 生成内容的论文。而且这些数据库包含的材料超出了科学期刊中经过同行评审的文章的范围。
与格雷的方法类似,这项搜索还发现了可能指向 LLM 的更微妙的痕迹:它查看了在科学文献中发现的 ChatGPT 首选的常用短语或词语的次数,并跟踪了它们在 OpenAI 的聊天机器人于 2022 年 11 月发布之前的几年(追溯到 2020 年)的流行程度是否发生了显着变化。研究结果表明,科学写作的词汇发生了一些变化——这种发展可能是由日益普及的聊天机器人的写作习惯引起的。“有一些证据表明,随着语言的正常发展,某些词语会随着时间的推移而稳步变化,”格雷说。“但这里有一个问题,即其中有多少是语言的长期自然变化,又有多少是不同的东西。”
ChatGPT 的症状
为了寻找 AI 可能参与论文制作或编辑的迹象,大众科学的搜索深入研究了“delve”这个词——正如一些非正式的 AI 制作文本监控者所指出的那样,该词在学术界的使用量异常激增。对其在 PubMed 目录中包含的约 3700 万篇生命科学和生物医学引文和论文摘要中的使用情况进行分析,突显了该词的流行程度。“delve”一词的使用量从 2020 年的 349 次增加到 2023 年的 2,847 次,到 2024 年迄今为止已出现 2,630 次——增加了 654%。在涵盖更广泛科学领域的 Scopus 数据库和 Dimensions 数据中,也看到了类似但不太明显的增长。
根据大众科学的分析,这些监控者标记为 AI 生成的流行语的其他术语也出现了类似的增长:“commendable”一词在 Scopus 跟踪的论文中出现了 240 次,在 Dimensions 跟踪的论文中出现了 10,977 次(2020 年)。这些数字在 2023 年分别飙升至 829 次(增加 245%)和 20,536 次(增加 87%)。而对于那些想要进行“细致”研究的人来说,也许具有讽刺意味的是,“meticulous”这个词在 2020 年至 2023 年间在 Scopus 上的使用量翻了一番。
不仅仅是文字
在一个学术界人士奉行“不发表就灭亡”的座右铭的世界里,有些人使用聊天机器人来节省时间或加强他们在英语方面的能力,这并不令人意外,因为在科学领域,英语通常是发表论文的必要条件。但是,将 AI 技术用作语法或句法助手可能会成为在科学过程的其他部分误用它的滑坡。有人担心,与 LLM 合著者一起撰写论文可能会导致关键人物完全由 AI 生成,或者导致同行评审外包给自动化评估人员。
这些并非纯粹是假设的场景。AI 确实已被用于制作科学图表和插图,这些图表和插图经常被包含在学术论文中——包括一个引人注目的离奇地被赋予了超常生殖器的啮齿动物——甚至取代实验中的人类参与者。根据一项关于 2023 年和 2024 年在 AI 会议上提交研究成果的科学家收到的反馈语言的预印本研究,AI 聊天机器人的使用可能已经渗透到同行评审过程本身。如果 AI 生成的判断与 AI 文本一起悄然进入学术论文,这让包括英国非营利组织出版伦理委员会理事会成员马特·霍奇金森在内的专家感到担忧,该委员会旨在促进符合道德规范的学术研究实践。聊天机器人“不擅长进行分析,”他说,“而这才是真正的危险所在。”
本文的一个版本题为“聊天机器人入侵”,经过改编后收录在 2024 年 7 月/8 月号的大众科学杂志中。